4 Development
When data science projects start, often the outcome is unknown. The work is inherently exploratory and experimental. In many cases this results in a more informal way of working. Frameworks and workflow choices to support this work also need to be designed differently.
4.1 Definition
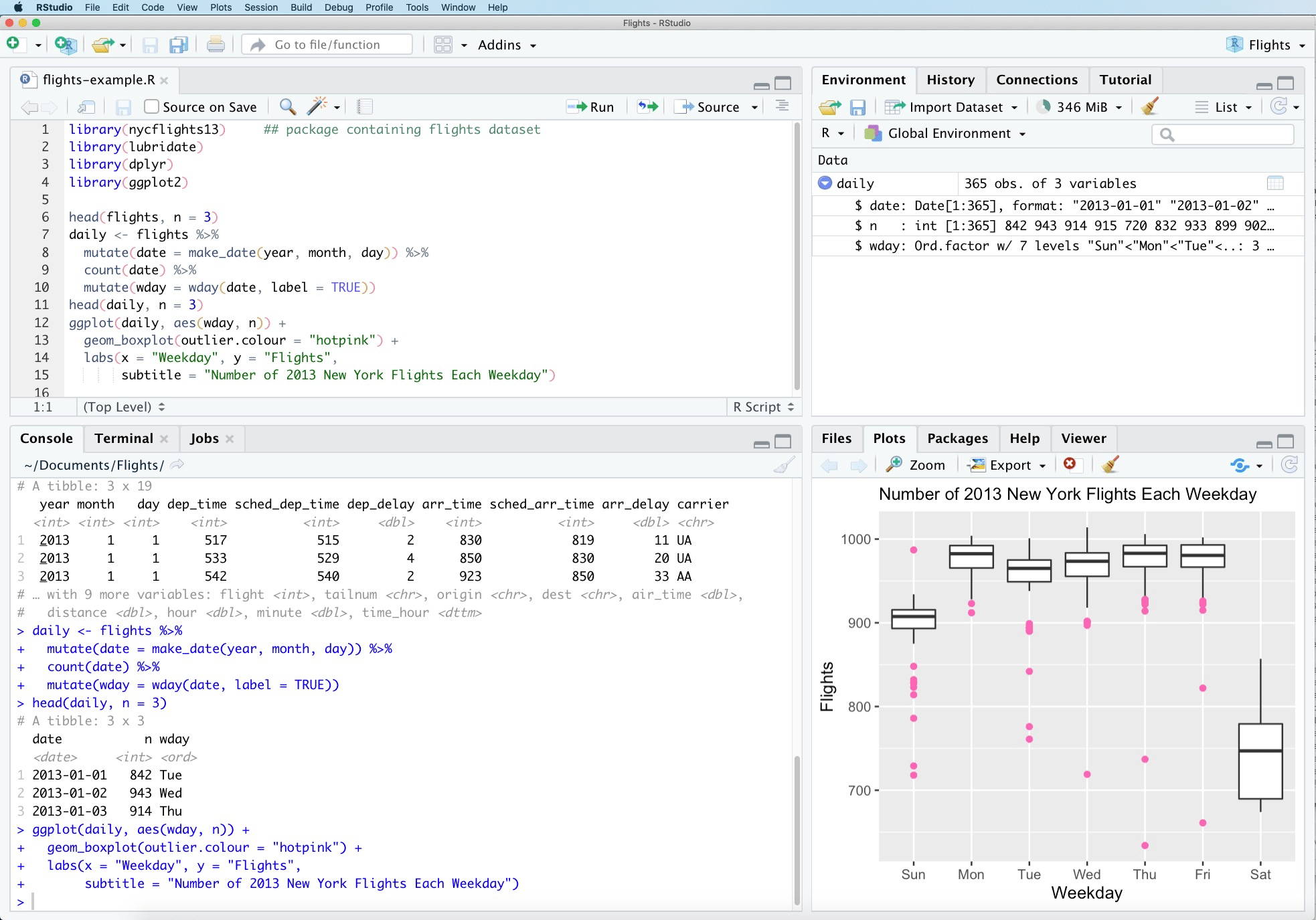
Development is a way of working, but it is also a technical term for a hardware and software environment. In many data science organisations, development is usually a logical (and physical) separation of tools, hardware and software that allow analysts to perform work that is not to be directly relied upon for real-world decision making. This type of environment is prone to running experimental workloads, tests and day-to-day development of projects and ideas by a data science team.
A key defining feature of development code is the colocation of what the code does and how the code is run. That is, the functional elements of the code and the orchestration of those elements are not separated.
4.2 Roles
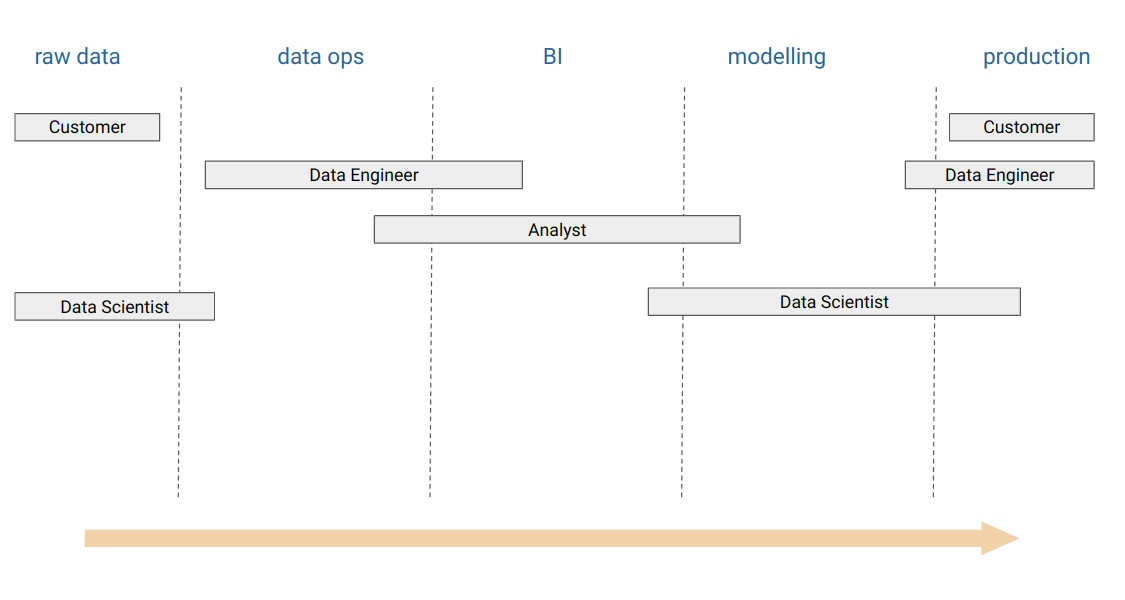
We can assess the various roles that take place in the development workflow cross sectionally by looking at the full life cycle from raw data through to a production deployed system.
In most organisations, not all roles will be present. In some organisations, there may even be more specialised roles. For example an MLOps engineer may handle the deployment of machine learning workloads, while a data engineer may focus entirely on data operations. In addition a data scientist may or may not be present entirely.
4.2.1 Customer
A customer (end-user) is a key role. Customers should be involved throughout the entire process but in particular are active in projects at the raw data and production stage to contextualize, understand and provide understanding of the raw data in addition to being the end-user of production systems.
4.2.2 Data Engineer
In many organisations an enrichment process from raw data into some kind of data warehouse environment is conducted by data engineers. A data engineer may also be responsible for provisioning infrastructure and assisting with production deployments.
4.2.3 Data Analyst
Once data is landed in a place where it is outside of front-end systems, analysts can typically use this data to perform analysis, Business intelligence (BI), report generation and dashboard building.
4.2.4 Data Scientist
The role of the data scientist can take many shapes. Typically, it is viewed as being of most value in the stage after basic data analysis when more advanced modelling statistical analysis and AI/ML applications are required. In reality, it is advisable for data scientists to be involved in the raw data stage with the customer. This aligns with earlier data analysis frameworks mentioned such as CRISM-DM where an iterative and collaborative approach is required from across all stages of the process.
4.3 Tools
Technical tools to support development workloads usually exist on the analysts local workstation. Most users will have an Integrated Development Environment (IDE) such as RStudio, VSCode or Positron. Some analysts prefer to have a Graphical User Interface (GUI) tool for analysis however this is not recommended when the intention is for the work to be relied upon for reasons we will explore later.