2 Data Science Frameworks
There are many approaches to tackling a data science project. Following a framework is important to ensuring successful delivery and management of a project. The key benefits of using a dedicated data science workflow are not only ensuring the work gets done right, but that it also provides a useful means for engaging stakeholders, providing project management updates and ensuring everyone is focused in the right areas.
2.1 Popular Frameworks
2.1.1 CRISP-DM
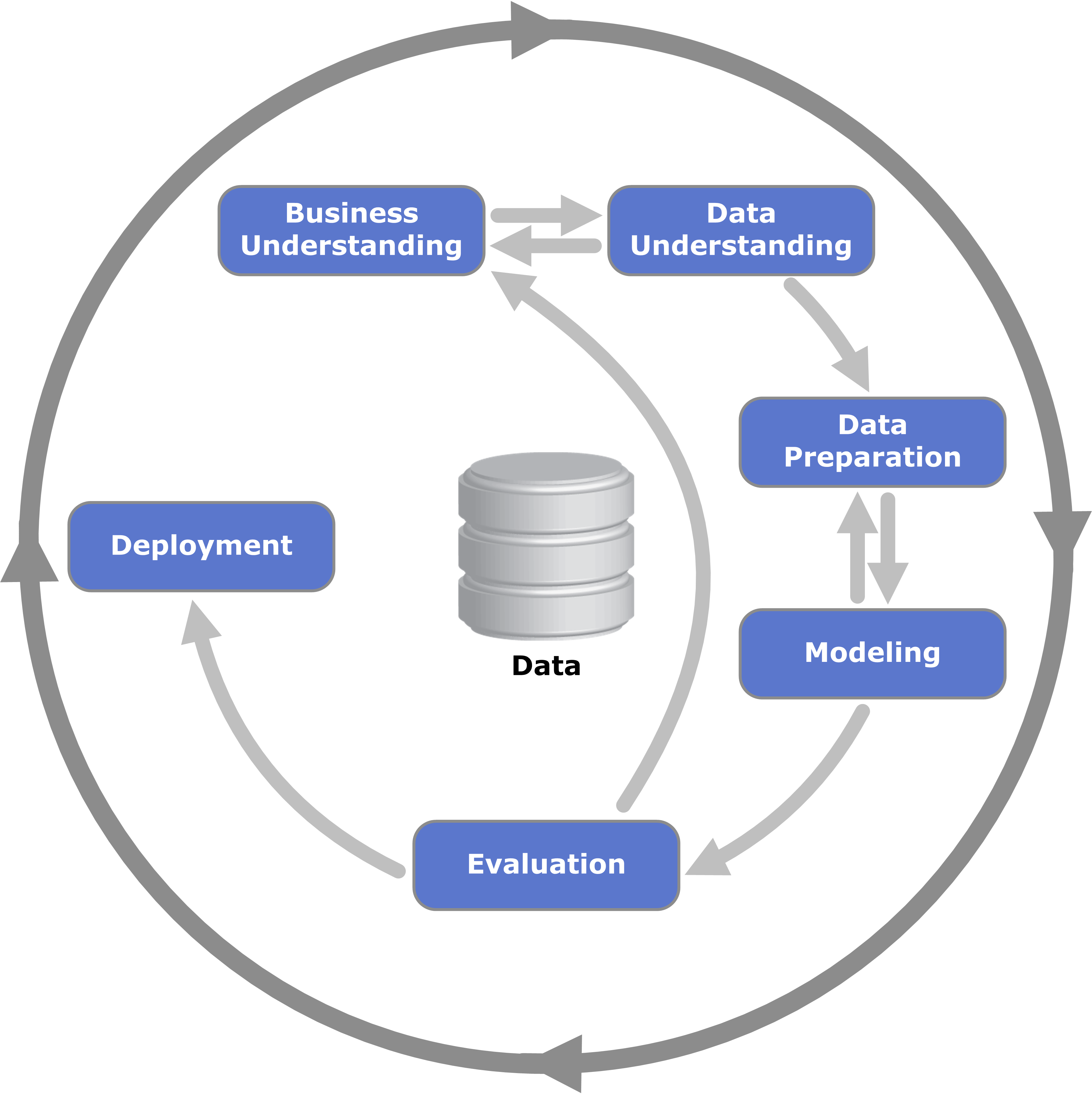
The Cross Industry Standard Practice for Data Mining (CRISP-DM)1 is a traditional framework for approaching data mining/data science/analytics projects. Developed in the 1990’s it has stood the test of time and remains a popular choice today for several reasons.
Firstly, it has a strong focus on understanding the business problem and guiding the exploration of the data with subject matter experts. Secondly, the framework provides for strict evaluation of solutions with business experts before deployment effort. Finally, the ethos of iterative, continual improvement is built in which aligns well with modern agile philosophies.
The key components of CRISP-DM are:
- Business Understanding
- Data Understanding
- Data Preparation
- Modelling
- Evaluation
- Deployment
A drawback of this framework is the way in which deployment is handled in modern use-cases. The need to manage the provision, hosting and monitoring of cloud or server resources has resulted in extensions to CRISP-DM.
2.1.2 Inner Loop vs Outer Loop
If we ignore the Deployment step in the CRISP-DM framework we have a nice workflow for completing ‘experimental’ development and modelling work.
At some point the analyst will want to deploy their work. A useful abstraction that separates the analytical work and the engineering tasks associated with deployment is through the inner loop vs outer loop concept.
The inner loop is the above mentioned CRISP-DM framework right up until deployment.
The outer loop involves the provision of computing infrastructure for model inference, model registration and versioning, deployment and endpoint provisioning, and finally monitoring and evaluation of the deployed model.
While this framework is commonly applied to deploying predictive models, adaptations can be made in the case of a dashboard, web-app or dynamic report output.
- Outer Loop
- Infrastructure Deployment
Inner Loop
- Business Understanding
- Data Understanding
- Data Preparation
- Modelling
- Evaluation
- Business Understanding
- Model Registration and Deployment
- Monitoring
2.2 Development vs Production
A key distinction introduced above is the separation of development practices from production practices. The typical project will primarily involve development practices outlined in the ‘Inner Loop’. When we refer to production work, it typically refers to work to support the deployment of development work in a context where it used to facilitate decision making. We will explore this concept further and analyse the key elements of ‘production’ code.
The use of the terms development and production here represent the intent of the workflow and not specifically a computing environment. In many organisations there are dedicated computing and infrastructure environments (often called ‘development’, ‘dev’, ‘test’, ‘sandbox’, ‘prod’, ‘uat’ etc.) to support the physical separation of these workflow paradigms. This will be explored later.